
Artificial Intelligence (AI) allows us to produce photos faster than ever before, but are they still ‘photos’ in the same sense of the word? AI allows us to make videos without the need to go anywhere to film them, but are they even ‘videos’ anymore?
1 MP・1344 × 896・2,3 MB

19 September 2021

There is a spiritual project that defines the notion of modern art.
Art is a reflection of experience, it tells a story and evokes emotions. Photos and videos show us how things were seen at a certain time, by an individual. They freeze moments in history, giving us the chance to reflect upon them. It seemed impossible to create an image without lived experience, until AI defied this very assumption. Given this visual contradiction, how do viewers treat AI-generated images?.
1 MP・1344 × 896・2,1 MB


The AI-generated image is in the unique predicament of being based on representations of human experience, but not a representation of the human experience itself. Informed by datasets containing billions of image-text pairs, AI-generated images are constructed out of pure logic as opposed to emotional intuition. 1 Essentially, text-to-image generation is an image-making process that is inherently detached from the nature of conscious human experience, so, to what extent can it be used to mimic the quality of human depth?
1 MP・1344 × 896・1,9 MB


American writer Susan Sontag, in her essay ‘The Aesthetics of Silence’, claims that every era must reinvent the project of ‘spirituality’ for itself. In my view, this denotes the use or presentation of something in a new way, to enact moments for us to re-assess our reality in the changing world. Today I see this act of reinvention as text-to-image generation.
1 MP・1344 × 896・2,3 MB

In the modern era, Sontag suggests that one the most active metaphors for the spiritual project is ‘art’. Supposedly, people turn to ‘art’, in place of religion, as the site in which consciousness confronts the meaning of life. The spiritual project, the path towards a higher level of knowing, is subjective to the individual. To Sontag, spirituality refers to the plans, terminologies, ideas of behaviour aimed at the resolution of deeply embedded tensions within a system (person, organisation, or society) inherent to the human condition; “at the completion of human consciousness, at transcendence.”
With this in mind, do AI-generated images resolve our desire to perceive existence better? In a sense, yes. For instance, if a person wants to create a photo of a dog but has no dog to take a photo of, text-to-image generation makes it possible. But is it still ‘a photo of a dog’ anymore? The event is faked, the dog and the action of capturing the scene never occurred, however the creator’s intention behind the image remains real.
1 MP・1344 × 896・1,9 MB

Sontag asserts that no matter what goal is set for art, it will prove restrictive when matched against the goals of consciousness. She suggests that art itself is a form of mystification that uses ‘cries of demystification’ to attack older artistic goals and supposedly replace them; redrawing outgrown maps of knowledge.
Interestingly, she suggests that our desire for demystification is powered by the unification of separate disciplines into the single category of ‘art’. A dilemma of the modern era. This creates the notion that all these disciplines, be it photography, painting, music, or dance, all serve to achieve the same goal: transcendence. However, given the subjective nature of this goal, a problematic arena for comparison arises, which causes the procedures and the very existence of these activities to be called to question (in the name of ‘art’).
I deem AI-generated images ‘art’, but in this way, it too assumes the role of achieving the same goal as all the other ‘art’ forms in my head. For instance, when the result I get from an AI-generated image fails to meet the emotional or spiritual response of a photographed image, I question the quality of this ‘art form’. Nevertheless, they let us feel as though what we want to see can be seen. Images of Narnia are just a few prompts away. Essentially, instead of showing us what a photo does, or what a painting does, AI-generated images show us something else: the human imagination interpreted by computer processes. Which, in it of itself, is quite spectacular.
1 MP・1344 × 896・2,2 MB

There are myths about art, but the newer one, the myth Sontag denotes as modern art, not only denies art as mere expression, but also describes it as the mind’s need or capacity for self-extrangement: to feel alienated from others and society as a whole. 2 In the modern era, art, mystification, is not the answer to full consciousness, but rather its antidote — evolved from consciousness itself.
For as long as I can remember, my spiritual project pertained to identity. As part of the prototyping stage of my graduation project, I adopt text-to-image generation as a forum to explore my own childhood nostalgia. In Singapore, I grew up in the ‘expat bubble’: an eco-system containing the amalgamation of various international cultures in an environment semi-secluded from the country’s local population. It has always been a peculiar thing for outsiders to understand, so it has been a desire of mine to find a better way to recognise the place I call home. Evidently, the development of an image series won’t construct my ‘identity’ per se, instead, it will serve to provide clarity.
1 MP・1344 × 896・2,5 MB


Sontag looks at ‘the aesthetics of silence’ in reference to the behaviour of the great religious mystics. To her, just as the activities of the mystic must end upon their completion of the spiritual project, when the mind unites with God and the body can rest at last, modern art craves peace in the form of ‘nothingness’. As a means of mimicking the completion of consciousness, Sontag suggests that “art must tend towards anti art — the elimination of the “subject” (the “object, the “image”) in order to substitute chance for intention, and the pursuit of silence.”
1 MP・1344 × 896・2,3 MB

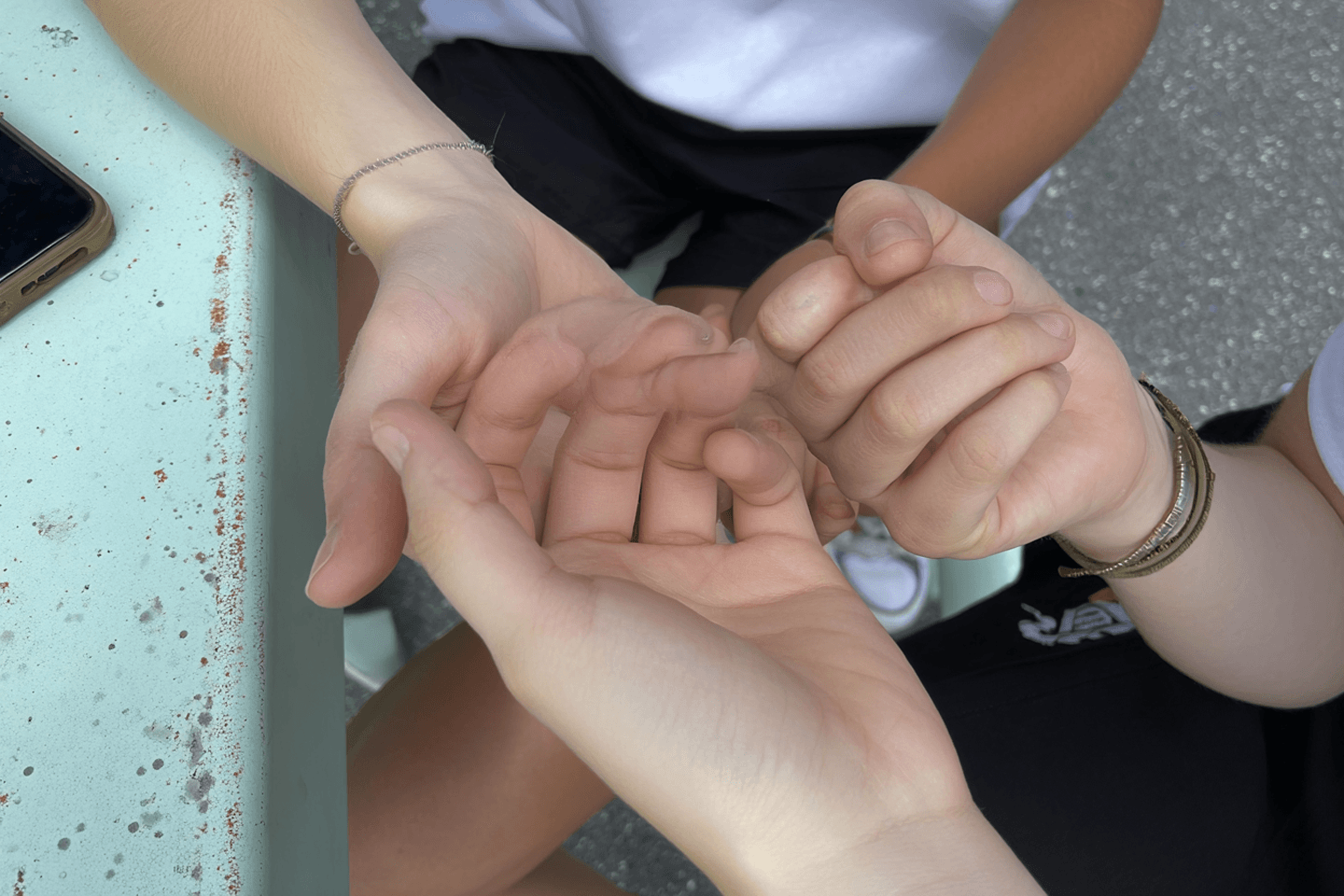
Sontag looks at ‘the aesthetics of silence’ in reference to the behaviour of the great religious mystics. To her, just as the activities of the mystic must end upon their completion of the spiritual project, when the mind unites with God and the body can rest at last, modern art craves peace in the form of ‘nothingness’. As a means of mimicking the completion of consciousness, Sontag suggests that “art must tend towards anti art — the elimination of the “subject” (the “object, the “image”) in order to substitute chance for intention, and the pursuit of silence.”
1 MP・1344 × 896・2,3 MB

19 September 2021

Silence & Presence in Vaysberg’s Photography
Ukrainian/Jewish photographer Daniel Vaysberg captures models in mundane places, insinuating the surrealist nature of urban environments. In his photographs for COEVAL (Issue 2, Fall Winter 2025/26), he employs candid framing and a causal setting to dramatise the presence of the model and her luxurious outfit. There is no visibly flamboyant display, no other people or sense of helpful assistance, there is no ‘life’ but the model’s. Effectively, she is portrayed lonesome but complete. In my view, Vaysberg eliminates the lively and uses ‘silence’ to introduce a powerful ‘aura’ that needs no further validation.


1 MP・1344 × 896・2 MB

19 September 2021

Viewers appear to garner spiritual meaning from images, AI-generated images, through what it allows them to see, as opposed to what it actually shows. AI-generated images have the ability to cure a creator’s desire to visually clarify mental concepts, and as a result, make them, me, feel as though clarity is within reach.
Written in 1967, ‘The Aesthetics of Silence’ remains quite telling of today’s contemporary art scene. However, it is an outlook on the way humanity adopts art that will, according to Sontag, reinvent itself in the future.
1 MP・1344 × 896・2,2 MB


The circumstances through which we come to know ourselves and the world around us drives the way we perceive images.
1 MP・1344 × 896・2 MB


In the book ‘Ways of Seeing’, author John Berger asserts the fact that “seeing comes before words”. He suggests that there is an ever-present disconnect between what we see and what we know, proposing that sight is the product of continuously active choices of looking that occur in accordance with “the relation between things and ourselves”. In this way, viewers don’t experience an image as an isolated event, rather, they perceive it in relation to its context. For instance, its placement on a billboard or its appearance on an instagram feed. As a result, our vision is a two-way street that originates from what is present to us as we are to it.
1 MP・1344 × 896・2 MB


According to Berger, every image embodies a way of seeing. However, AI-generated images no longer require a person to actively choose a subject matter or the way it is being framed, for the computer is able to do all that automatically. Given our history with older image-making methods, text-to-image generation is an odd and often misunderstood tool. For many, AI-generated images are a hack, and low-blow to the ‘art’ of image-making. They mimic the strenuous human effort behind photography and painting in a matter of seconds to produce similar, or even arguably better results.
To some, it seems unfair and perhaps intimidating, so a cautionary question arises: Is text-to-image generation something to accept passively? In my view, automation is the public’s key concern about AI and the future of culture. Raising questions like: what happens when humans are no longer in control? And: have we already lost control?
1 MP・1344 × 896・1,9 MB


In 2018, Russian artist Lev Manovich suggests that there is a skewed perception of AI, specifically in the way we think it is affecting our lives. According to an article published in 2006 by The Washington Post, there is an ‘AI effect’: when we know how a machine does something ‘intelligent’, it ceases to be regarded as intelligent. For instance, existing tasks that have been automated using AI, like Google’s Smart Reply function, is an out of sight out of mind topic that has receded into the grey zone of our day-to-day lives. Consequently, the more challenging, not-yet-perfected AI jobs like natural speech understanding, automated translation, and the recognition of objects in photos, are magnified to the extent in which our perception of ‘AI’ revolves around these more obvious features. So, is AI mediating the way society functions, our behaviour, without our apparent knowledge?
1 MP・1344 × 896・1,8 MB


In the realm of image-making, there is a plethora of less obvious AI-automated processes that are intentionally and unintentionally used to guide aesthetic creation and aesthetic choices that go unseen. For example, Instagram’s Explore screen recommends images and videos to each user based on a combination of many factors (not based on what the user liked in the past). 3 The Huawei Mate 10 phone camera (released 10/2017) uses AI to analyze what it sees to then select the appropriate parameters for capturing a given scene before you decide to take a photo. 4 Evidently, AI influences our way of seeing in many ways other than text-to-image generation, so how can we combat this to protect our authentic intentions?
1 MP・1344 × 896・2 MB

Manovich alluded to the implementation of customizable features to increase the ‘aesthetic diversity’ of the AI algorithms and user interfaces of various digital services, apps, and products, as a means of harnessing AI to our unique benefit. In Midjourney, I exercised this notion by creating a moodboard of my own photographs to serve as the direct visual inspiration for the images I would later create. In this way, as opposed to submitting myself to Midjourney’s default aesthetics, I curated my own style (avant garde framing and cool colour tones) to visually interpret my prompts. However, as part of my work flow, I used chatGPT to rewrite my specific ideas of childhood in Singapore in a way that would be well-interpreted by the Midjourney bot. This worked well with my intentions, but the extent to which I am in control of this image-making process remains foggy.
1 MP・1344 × 896・2,2 MB

Interestingly, the founder of Midjourney David Holz compares AI to water. He argues that while we can ‘drown’ ourselves in AI, it can also sustain us if we learn to live and work with it. According to him, many people view AI to be some kind of adversary, a tiger that might eat us. However, it is important to remember that AI has no intent. It is directionless, so its ‘flow’ can be navigated, hosted, or channelled as a source of inspiration and power.
Whether or not AI becomes a tool that liberates our will appears to be entirely up to our collective use of it. One could argue that those in power have more control of this decision than we do, but I believe, in terms of the enormity of public data AI drives on, that it is the actions of the general community that weighs more heavily.
1 MP・1344 × 896・2,5 MB

In my AI-generated images, I intentionally dictate the exclusion of eyes, full human figures, and vast landscapes to create an ambiguity that draws the viewer’s focus to the scenario, as opposed to a specific character or location. In this way, I aim to create a ‘vibe’ that translates the idea of my upbringing in Singapore into core universal feelings, like warmth, care, and safety, that the viewer can appreciate no matter how familiar they are with the island’s lifestyle.
1 MP・1344 × 896・2,9 MB


In terms of text-to-image generation, the dynamic between the creator and AI is exponentially advancing. I think the existing level of aesthetic diversity available platforms, such as Midjourney, is a good step in the direction towards harnessing AI to produce personally engaged, meaningful results like the more direct activities in life.
Humans are complex creatures, so a person’s personal context may not be the only factor guiding their perception of the world. While our preconceived notions of life aren’t always deliberate, by recontextualising our opinions and learning more about how AI mediates our access to images, we will not only see them more clearly, but also obtain the power to utilize them more meaningfully.
1 MP・1344 × 896・2,7 MB

The viewer’s affinity towards AI-generated images is linked to how realistic they look.
1 MP・1344 × 896・2 MB

Japanese roboticist Masahiro Mori, in his essay “The Uncanny Valley”, hypothesized that a person’s response to a human-like robot, as it attempts to approach a lifelike appearance, would abruptly shift from empathy to revulsion. 5 Related articles suggest that this response may be due to an evolutionary, subconscious signal for pathogen avoidance or threat detection.
According to Mori, the prevalence of monotonic relationships (when two variables share a uni-directional correlation) in everyday phenomena, makes it easy for us to fall under the illusion that all relationships behave this way. For instance, in the context of robotics, engineers may be under the impression that the more human-like a robot appears, the more friendly they would seem to people. Mori suggests the opposite.

1 MP・1344 × 896・2 MB

AI-generated images attempt to resemble camera-shot photographs. Although artificial, they mimic representations of the human experience at a level of detail that can make the viewer second guess apparent distortions of the real world. However, to what extent can AI-generated images garner photo-like responses from its audience?
In the case of human-like robots, Mori’s explanations appear to assume that the viewer is always aware of the fact that the human-like robot, no matter how lifelike it appears, is a robot. This suggests that viewer’s revulsion stems from visual confusion as opposed to knowledge confusion.
On the contrary, the viewer of an AI-generated image may not know that it has been AI-generated. People reportedly experience the uncanny effect, when they notice subtle inconsistencies in an AI-generated image but cannot yet identify what is wrong. In this scenario, does the viewer’s revulsion stem from visual confusion, knowledge confusion (not knowing it is AI-generated), or both?
1 MP・1344 × 896・2,8 MB

Nevertheless, I apply Mori’s ‘Uncanny Valley’ graph to AI-generated images of increasing hyperrealism to theorise how the viewer would respond to them as they attempt to reach the appearance of real life photos (see Fig. 3).

a. When both human affinity and photo likeness is low, this marks the position of blurry AI-generated images (see Fig. 4). The subject matter is unintelligible, so the viewer cannot make sense of their connection to the real world.

b. When both human affinity and photo likeness is high, this marks the position of realistic images that look obviously AI-generated (high saturation, inaccurate texture) (see Fig. 5). The subject matter is intelligible, so the viewer makes sense of their connection to the real world but cannot envision its presence realistically.

c. When human affinity is low and photo likeness is high, this marks the position of hyperrealistic AI-generated images (see Fig. 6). The subject matter is not only intelligible, they look just like they would in a camera-shot photograph, so the viewer makes sense of their connection to the real world and can envision its presence realistically. However, upon further analysis, the subtle errors (anatomical mishaps) of these images creates a cognitive dissonance: the viewer sees a very convincing ‘photo’ that displays life in the way a photo usually would. This is the uncanny valley.

d. When both human affinity and photo likeness is high again, this marks the position of camera-shot photographs (see Fig. 7). The subject matter in these images are intelligible, so the viewer makes sense of their connection to the real world and can envision its presence realistically.

1 MP・1344 × 896・2,2 MB

It seems like the only barrier stopping the AI-generated image from achieving high human affinity and photo likeness is its subtle errors. Given the current trajectory of AI technology, it is only a matter of time until this barrier is no longer. At the moment, viewers’ cognitive dissonance towards hyperrealistic AI-generated images appears to prevent them from pleasantly accessing the visual as a friendly gesture. So, how can we create AI-generated images that appear wholesome?
Mori suggests that the meaning behind an object’s conceptual function overpowers its physical appearance. In other words, it is an object’s purpose or function, rather than its appearance, that ultimately defines its meaning to us. For instance, Mori states that although eyeglasses do not resemble real eye-balls, one could say that their design has created a charming pair of new eyes. Thus, he predicts that it is possible to create a safe level of affinity by deliberately pursuing a less lifelike design. In this way, the user is no longer at risk to cognitive dissonance, and instead, welcomes the object’s presence positively.
Published in 2012, Mori’s research uses graphs to model the human response to artificial lifelike appearances. However, the spiritual nature of our behaviour (denoted by Sontag) suggests that this method of analysis is inadequate. To elaborate, the uncanny feeling may not only pertain to the detection of unlifelike traits as a biological survival tactic, but also an ontological uneasiness about the nature of human consciousness.
‘The Uncanny Valley’ hypothesis suggests that viewers experience emotional meaning in AI-generated images if they are able to connect the subject matter to a real world context, and when their understanding of its intention is positive.
1 MP・1344 × 896・2,1 MB
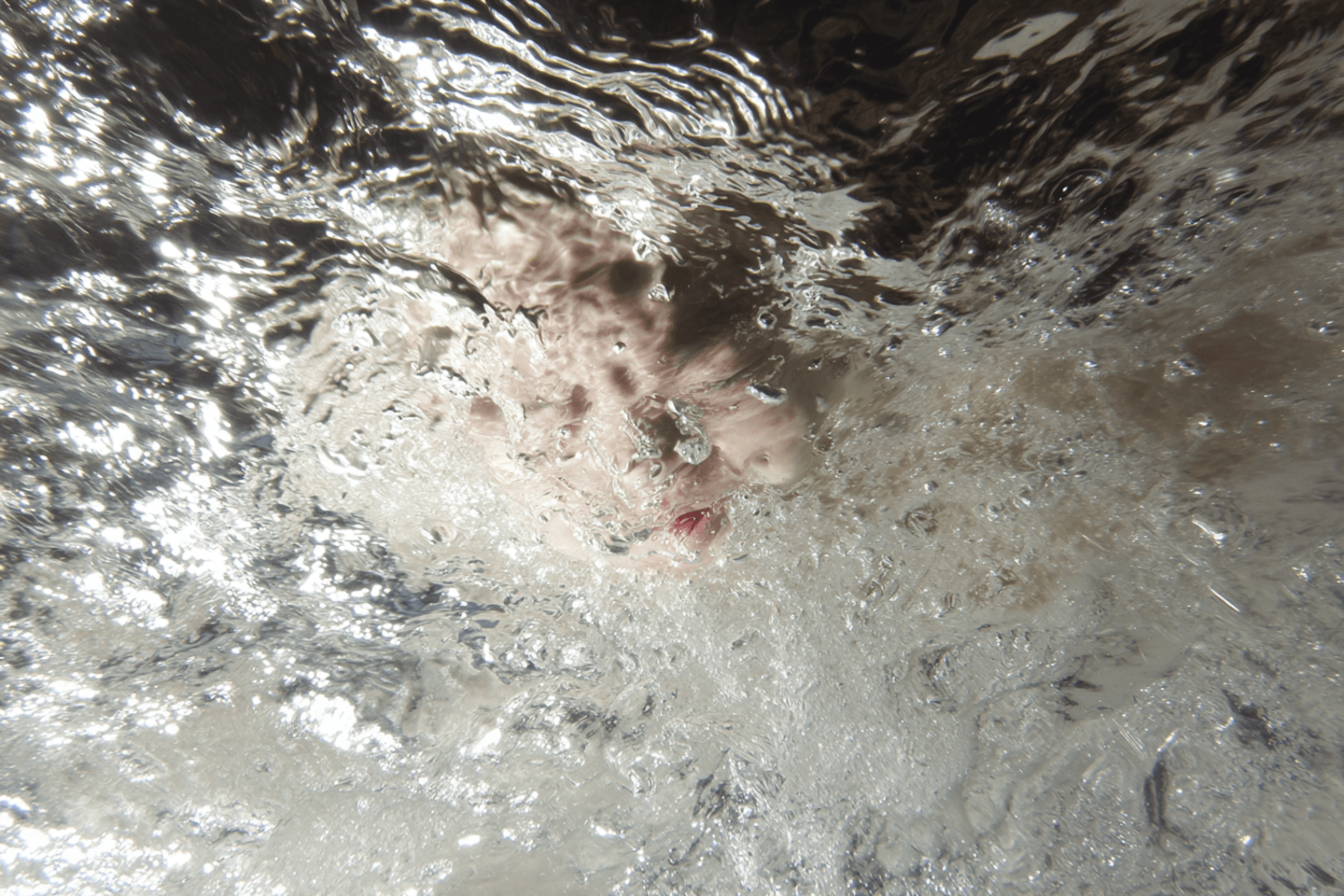
In my project, I use AI-generated images to illustrate nostalgic warmth. I want my images to look wholesome and positive. Thus, to achieve a pleasant viewer response, Mori’s theory suggests that AI-generated images should not look almost identical to a camera-shot photograph. With this in mind, my images intend to accurately mimic the natural and urban spaces in Singapore while leaving subtle errors, like fusing objects and unidentifiable limbs, untouched. As a result, I portray my images not as photographed scenes, but as AI-generated interpretations of my childhood culture and community, a personally meaningful exhibit rather than an act of deception.
1 MP・1344 × 896・2,7 MB